本文简要梳理了 f2fs 文件系统的组织方式和操作流程。
f2fs 文件组织形式和典型流程
重要结构
文件结构
文件数据的组织方式一般时被设计为inode-data模式,即 每一个文件都具有一个inode,这个inode记录data的组织关系,这个关系称为文件结构 。例如用户需要访问A文件的第1000个字节,系统就会先根据A文件的路径找到的A的inode,然后从inode找到第1000个字节所在的物理地址,然后从磁盘读取出来。那么F2FS的文件结构是怎么样的呢?
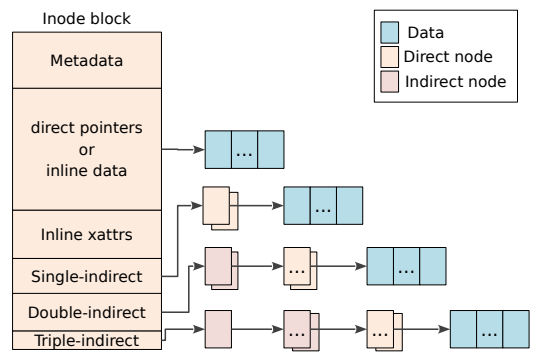
如上图,F2FS中的一个inode,包含两个主要部分: metadata部分,和数据块寻址部分。我们重点观察数据块寻址部分,分析inode时如何将数据块索引出来。在图中,数据块寻址部分包含direct pointers,single-indirect,double-indirect,以及triple-indirect。它们的含义分别是:
direct pointer: inode内直接指向数据块(图右上角Data)的地址数组,即inode->data模式 。
single-indirect pointer: inode记录了两个single-indirect pointer(图右上角Direct node),每一个single-indirect pointer存储了多个数据块的地址,即inode->direct_node->data模式 。
double-indirect: inode记录了两个double-indirect pointer(图右上角indirect node),每一个double-indirect pointer记录了许多single-indirect pointer,每一个single-indirect pointer指向了数据块,即inode->indirect_node->direct_node->data模式 。
triple-indirect: inode记录了一个triple-indirect pointer(图右上角indirect node),每一个triple-indirect pointer记录了许多double-indirect pointer,每一个double-indirect pointer记录了许多single-indirect pointer,最后每一个single-indirect pointer指向了数据块。即inode->indirect_node->indirect_node->direct_node->data模式 。
因此,我们可以发现,F2FS的inode结构采取indirect_node,首先在inode内部寻找物理地址,如果找不到再去direct_node找,层层深入。
目录结构
directory entry
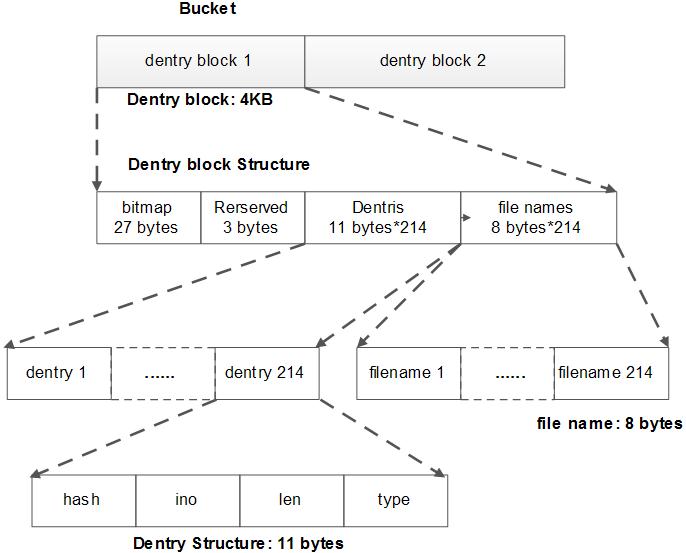
每个目录 entry 包括 hash / ino / len / type 四个成员,占用 11 bytes。每个 entry 代表一个子目录、符号链接或者普通文件。
1 2 3 4 5 6 A directory entry occupies 11 bytes, which consists of the following attributes. - hash hash value of the file name - ino inode number - len the length of file name - type file type such as directory, symlink, etc
directory block
专门存储 directory entry 的 block 叫做 diretory block。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 A dentry block consists of 214 dentry slots and file names. Therein a bitmap is used to represent whether each dentry is valid or not. A dentry block occupies 4KB with the following composition. Dentry Block(4 K) = bitmap (27 bytes) + reserved (3 bytes) + dentries(11 * 214 bytes) + file name (8 * 214 bytes) +--------+----------+----------+------------+ | bitmap | reserved | dentries | file names | +--------+----------+----------+------------+ [Dentry Block: 4KB] . . . . . . +------+------+-----+------+ | hash | ino | len | type | +------+------+-----+------+ [Dentry Structure: 11 bytes]
bucket
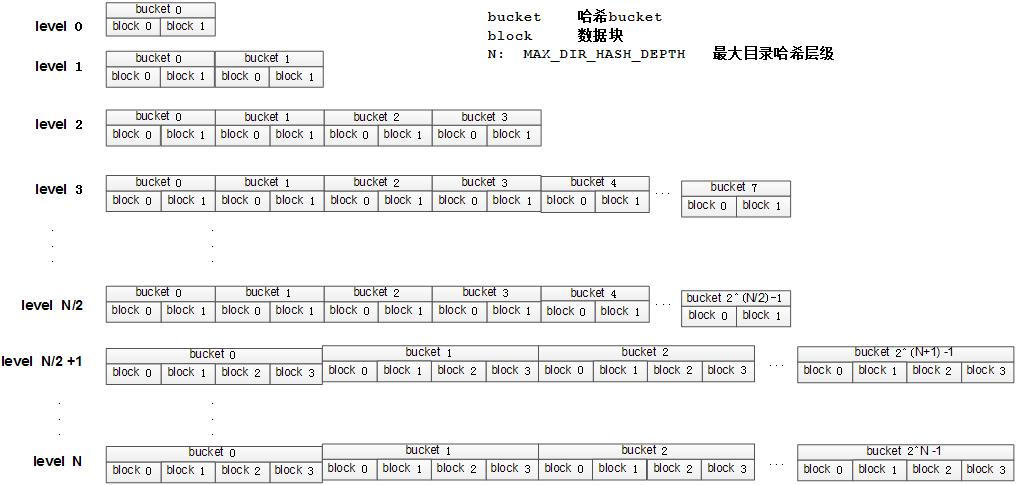
很容易想到目录结构是一系列的哈希表连续地存储在一个文件中,每个哈希表具有一组相当大的 buckets。查找过程从第一个哈希表到下一个哈希表,在每一个阶段对合适的bucket 执行线性查找,直到找到文件名或者查找到最后的那个哈希表。在查找过程中,在合适的 bucket 中的任意空闲空间都会被记录,以防需要创建文件名的时候用到。
F2FS 对目录结构实现了多级哈希表,每一级都有一个使用专用数字的哈希 bucket 的哈希表,如下所示。注意,“A(2B)”表示一个哈希 bucket 包含两个数据块。
1 2 3 4 5 6 7 8 9 10 11 12 ---------------------- A : bucket 哈希bucket B : block 数据块 N : MAX_DIR_HASH_DEPTH 最大目录哈希层级 ---------------------- level #0: A(2B) level #1: A(2B) - A(2B) level #2: A(2B) - A(2B) - A(2B) - A(2B) . . . . . level #N/2: A(2B) - A(2B) - A(2B) - A(2B) - A(2B) - ... - A(2B) . . . . . level #N: A(4B) - A(4B) - A(4B) - A(4B) - A(4B) - ... - A(4B)
F2FS 在目录中查找文件名时,首先计算文件名的哈希值,然后在 level #0 中扫描哈希值查找包含文件名和文件的 inode 的目录项。如果没有找到,F2FS在 level #1 中扫描下一个哈希表,用这种方式,F2FS 以递增的方式扫描每个 level 的哈希表(如果上一 level 中没有查找到结果),在每个 level中,F2FS 仅需要扫描一个bucket,而该 bucket 的号是由文件名的哈希值与该 level 中的 buckets 个数的相除取余得到的。也就是每个 level 中需要扫描的一个 bucket 由下式确定的,查找复杂度是 O(log(# of files))
bucket number to scan in level #n = (hash value) % (# of buckets in level #)
文件操作流程
file open
函数调用流程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 open sys_call -> do_sys_open -> do_sys_openat2 -> get_unused_fd_flags do_filp_open -> path_openat -> alloc_empty_file while( link_path_walk open_last_lookups [lookup and maybe create] -> lookup_open -> d_lookup [find dentry in cache] dir_inode->i_op->lookup -> f2fs_lookup dir_inode->i_op->create -> f2fs_create ) do_open -> vfs_open -> do_dentry_open -> f2fs_file_open fsnotify_open and fd_install [load fd in cur task_struct]
相关回调函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 static int f2fs_create (struct inode *dir, struct dentry *dentry, umode_t mode, bool excl) { struct super_block *sb = struct f2fs_sb_info *sbi = struct inode *inode ; nid_t ino = 0 ; int err; f2fs_balance_fs(sbi); inode = f2fs_new_inode(dir, mode); if (IS_ERR(inode)) return PTR_ERR(inode); if (!test_opt(sbi, DISABLE_EXT_IDENTIFY)) set_cold_file(sbi, inode, dentry->d_name.name); inode->i_op = &f2fs_file_inode_operations; inode->i_fop = &f2fs_file_operations; inode->i_mapping->a_ops = &f2fs_dblock_aops; ino = inode->i_ino; err = f2fs_add_link(dentry, inode); if (err) goto out; alloc_nid_done(sbi, ino); if (!sbi->por_doing) d_instantiate(dentry, inode); unlock_new_inode(inode); return 0 ; out: clear_nlink(inode); unlock_new_inode(inode); iput(inode); alloc_nid_failed(sbi, ino); return err; }
创建 inode:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 static struct inode *f2fs_new_inode (struct inode *dir, umode_t mode) { struct super_block *sb = struct f2fs_sb_info *sbi = nid_t ino; struct inode *inode ; bool nid_free = false ; int err; inode = new_inode(sb); if (!inode) return ERR_PTR(-ENOMEM); mutex_lock_op(sbi, NODE_NEW); if (!alloc_nid(sbi, &ino)) { mutex_unlock_op(sbi, NODE_NEW); err = -ENOSPC; goto fail; } mutex_unlock_op(sbi, NODE_NEW); inode->i_uid = current_fsuid(); if (dir->i_mode & S_ISGID) { inode->i_gid = dir->i_gid; if (S_ISDIR(mode)) mode |= S_ISGID; } else { inode->i_gid = current_fsgid(); } inode->i_ino = ino; inode->i_mode = mode; inode->i_blocks = 0 ; inode->i_mtime = inode->i_atime = inode->i_ctime = CURRENT_TIME; inode->i_generation = sbi->s_next_generation++; err = insert_inode_locked(inode); if (err) { err = -EINVAL; nid_free = true ; goto out; } mark_inode_dirty(inode); return inode; out: clear_nlink(inode); unlock_new_inode(inode); fail: iput(inode); if (nid_free) alloc_nid_failed(sbi, ino); return ERR_PTR(err); }
简单来说,f2fs_new_inode() 有以下流程:
通过 VFS 层 new_inode() 通过 kmalloc 获得 inode 实例
填充必要的具体文件系统参数到 inode
alloc_nid() 分配 inode->ino
inode 插入到 VFS 层私有的 inode_hashtable,自身关联 inode->i_hash
标记 inode 为 dirty
返回 inode 实例
分配 nid:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 bool alloc_nid (struct f2fs_sb_info *sbi, nid_t *nid) { struct f2fs_nm_info *nm_i = struct free_nid *i =NULL ; struct list_head *this ; retry: mutex_lock(&nm_i->build_lock); if (!nm_i->fcnt) { build_free_nids(sbi); if (!nm_i->fcnt) { mutex_unlock(&nm_i->build_lock); return false ; } } mutex_unlock(&nm_i->build_lock); spin_lock(&nm_i->free_nid_list_lock); if (!nm_i->fcnt) { spin_unlock(&nm_i->free_nid_list_lock); goto retry; } BUG_ON(list_empty(&nm_i->free_nid_list)); list_for_each(this, &nm_i->free_nid_list) { i = list_entry(this, struct free_nid, list ); if (i->state == NID_NEW) break ; } BUG_ON(i->state != NID_NEW); *nid = i->nid; i->state = NID_ALLOC; nm_i->fcnt--; spin_unlock(&nm_i->free_nid_list_lock); return true ; }
nid freelist 不一定是完整的,当 free nid 不够了的时候就会重新进行构建。
关联 dentry,通过特定的哈希算法定位并初始化 dentry,更新 parent inode 的信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 int f2fs_add_link (struct dentry *dentry, struct inode *inode) { unsigned int bit_pos; unsigned int level; unsigned int current_depth; unsigned long bidx, block; f2fs_hash_t dentry_hash; struct f2fs_dir_entry *de ; unsigned int nbucket, nblock; struct inode *dir = struct f2fs_sb_info *sbi = const char *name = dentry->d_name.name; size_t namelen = dentry->d_name.len; struct page *dentry_page =NULL ; struct f2fs_dentry_block *dentry_blk =NULL ; int slots = GET_DENTRY_SLOTS(namelen); int err = 0 ; int i; dentry_hash = f2fs_dentry_hash(name, dentry->d_name.len); level = 0 ; current_depth = F2FS_I(dir)->i_current_depth; if (F2FS_I(dir)->chash == dentry_hash) { level = F2FS_I(dir)->clevel; F2FS_I(dir)->chash = 0 ; } start: if (current_depth == MAX_DIR_HASH_DEPTH) return -ENOSPC; if (level == current_depth) ++current_depth; nbucket = dir_buckets(level); nblock = bucket_blocks(level); bidx = dir_block_index(level, (le32_to_cpu(dentry_hash) % nbucket)); for (block = bidx; block <= (bidx + nblock - 1 ); block++) { mutex_lock_op(sbi, DENTRY_OPS); dentry_page = get_new_data_page(dir, block, true ); if (IS_ERR(dentry_page)) { mutex_unlock_op(sbi, DENTRY_OPS); return PTR_ERR(dentry_page); } dentry_blk = kmap(dentry_page); bit_pos = room_for_filename(dentry_blk, slots); if (bit_pos < NR_DENTRY_IN_BLOCK) goto add_dentry; kunmap(dentry_page); f2fs_put_page(dentry_page, 1 ); mutex_unlock_op(sbi, DENTRY_OPS); } ++level; goto start; add_dentry: err = init_inode_metadata(inode, dentry); if (err) goto fail; wait_on_page_writeback(dentry_page); de = &dentry_blk->dentry[bit_pos]; de->hash_code = dentry_hash; de->name_len = cpu_to_le16(namelen); memcpy (dentry_blk->filename[bit_pos], name, namelen); de->ino = cpu_to_le32(inode->i_ino); set_de_type(de, inode); for (i = 0 ; i < slots; i++) test_and_set_bit_le(bit_pos + i, &dentry_blk->dentry_bitmap); set_page_dirty(dentry_page); update_parent_metadata(dir, inode, current_depth); F2FS_I(inode)->i_pino = dir->i_ino; fail: kunmap(dentry_page); f2fs_put_page(dentry_page, 1 ); mutex_unlock_op(sbi, DENTRY_OPS); return err; }
f2fs_lookup 中也实现了上述的流程。(实际上我看的更新的内核版本,目录项查找流程已经写进 __f2fs_find_entry 函数里了)
write operation
f2fs 在 vfs 的注册函数如下:
1 2 3 4 5 6 7 8 9 10 11 12 const struct file_operations f2fs_file_operations = .write = do_sync_write, .aio_write = generic_file_aio_write, .splice_write = generic_file_splice_write, }; const struct address_space_operations f2fs_dblock_aops = .writepage = f2fs_write_data_page, .writepages = f2fs_write_data_pages, .write_begin = f2fs_write_begin, .write_end = nobh_write_end, };
f2fs_write_begin() 为写入操作准备了 page,并通过 pagep 指向它
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 static int f2fs_write_begin (struct file *file, struct address_space *mapping, loff_t pos, unsigned len, unsigned flags, struct page **pagep, void **fsdata) { struct inode *inode = struct f2fs_sb_info *sbi = struct page *page ; pgoff_t index = ((unsigned long long ) pos) >> PAGE_CACHE_SHIFT; struct dnode_of_data dn ; int err = 0 ; *fsdata = NULL ; f2fs_balance_fs(sbi); page = grab_cache_page_write_begin(mapping, index, flags); if (!page) return -ENOMEM; *pagep = page; mutex_lock_op(sbi, DATA_NEW); set_new_dnode(&dn, inode, NULL , NULL , 0 ); err = get_dnode_of_data(&dn, index, 0 ); if (err) { mutex_unlock_op(sbi, DATA_NEW); f2fs_put_page(page, 1 ); return err; } if (dn.data_blkaddr == NULL_ADDR) { err = reserve_new_block(&dn); if (err) { f2fs_put_dnode(&dn); mutex_unlock_op(sbi, DATA_NEW); f2fs_put_page(page, 1 ); return err; } } f2fs_put_dnode(&dn); mutex_unlock_op(sbi, DATA_NEW); if ((len == PAGE_CACHE_SIZE) || PageUptodate(page)) return 0 ; if ((pos & PAGE_CACHE_MASK) >= i_size_read(inode)) { unsigned start = pos & (PAGE_CACHE_SIZE - 1 ); unsigned end = start + len; zero_user_segments(page, 0 , start, end, PAGE_CACHE_SIZE); return 0 ; } if (dn.data_blkaddr == NEW_ADDR) { zero_user_segment(page, 0 , PAGE_CACHE_SIZE); } else { err = f2fs_readpage(sbi, page, dn.data_blkaddr, READ_SYNC); if (err) { f2fs_put_page(page, 1 ); return err; } } SetPageUptodate(page); clear_cold_data(page); return 0 ; }
f2fs_write_begin() 这个过程会被 VFS 调用,然后得到 page 的 VFS 将 write(fd, buf, size) 需要写入的 buf 内容拷贝到该 page。VFS 拷贝完成后,还会调用 write_end() 作为写入操作的结束调用,主要是为此前已上锁的 page 进行解锁
普通文件的默认写策略是 writeback,VFS 通过提供 writepage() 等定制点来实现具体文件系统的写回操作。前面已提到 F2FS 使用 f2fs_write_data_page() 和 f2fs_write_data_pages() 来完成这个操作
写回线程的调用路径:
1 2 3 4 5 6 bdi_writeback_thread wb_do_writeback wb_writeback __writeback_single_inode do_writepages a_ops->writepages
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 static int f2fs_write_data_page (struct page *page, struct writeback_control *wbc) { struct inode *inode = struct f2fs_sb_info *sbi = loff_t i_size = i_size_read(inode); const pgoff_t end_index = ((unsigned long long ) i_size) >> PAGE_CACHE_SHIFT; unsigned offset; int err = 0 ; if (page->index < end_index) goto out; offset = i_size & (PAGE_CACHE_SIZE - 1 ); if ((page->index >= end_index + 1 ) || !offset) { if (S_ISDIR(inode->i_mode)) { dec_page_count(sbi, F2FS_DIRTY_DENTS); inode_dec_dirty_dents(inode); } goto unlock_out; } zero_user_segment(page, offset, PAGE_CACHE_SIZE); out: if (sbi->por_doing) goto redirty_out; if (wbc->for_reclaim && !S_ISDIR(inode->i_mode) && !is_cold_data(page)) goto redirty_out; mutex_lock_op(sbi, DATA_WRITE); if (S_ISDIR(inode->i_mode)) { dec_page_count(sbi, F2FS_DIRTY_DENTS); inode_dec_dirty_dents(inode); } err = do_write_data_page(page); if (err && err != -ENOENT) { wbc->pages_skipped++; set_page_dirty(page); } mutex_unlock_op(sbi, DATA_WRITE); if (wbc->for_reclaim) f2fs_submit_bio(sbi, DATA, true ); if (err == -ENOENT) goto unlock_out; clear_cold_data(page); unlock_page(page); if (!wbc->for_reclaim && !S_ISDIR(inode->i_mode)) f2fs_balance_fs(sbi); return 0 ; unlock_out: unlock_page(page); return (err == -ENOENT) ? 0 : err; redirty_out: wbc->pages_skipped++; set_page_dirty(page); return AOP_WRITEPAGE_ACTIVATE; }
其中 struct dnode_of_data 是寻址用到的数据结构,用于物理地址寻址:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct dnode_of_data { struct inode *inode ; struct page *inode_page ; struct page *node_page ; nid_t nid; unsigned int ofs_in_node; bool inode_page_locked; block_t data_blkaddr; };
调用的函数:
1 2 3 4 5 6 7 8 9 static inline void set_new_dnode (struct dnode_of_data *dn, struct inode *inode, struct page *ipage, struct page *npage, nid_t nid) { memset (dn, 0 , sizeof (*dn)); dn->inode = inode; dn->inode_page = ipage; dn->node_page = npage; dn->nid = nid; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 int get_dnode_of_data (struct dnode_of_data *dn, pgoff_t index, int ro) { struct f2fs_sb_info *sbi = struct page *npage [4]; struct page *parent ; int offset[4 ]; unsigned int noffset[4 ]; nid_t nids[4 ]; int level, i; int err = 0 ; level = get_node_path(index, offset, noffset); nids[0 ] = dn->inode->i_ino; npage[0 ] = get_node_page(sbi, nids[0 ]); if (IS_ERR(npage[0 ])) return PTR_ERR(npage[0 ]); parent = npage[0 ]; nids[1 ] = get_nid(parent, offset[0 ], true ); dn->inode_page = npage[0 ]; dn->inode_page_locked = true ; for (i = 1 ; i <= level; i++) { bool done = false ; if (!nids[i] && !ro) { mutex_lock_op(sbi, NODE_NEW); if (!alloc_nid(sbi, &(nids[i]))) { mutex_unlock_op(sbi, NODE_NEW); err = -ENOSPC; goto release_pages; } dn->nid = nids[i]; npage[i] = new_node_page(dn, noffset[i]); if (IS_ERR(npage[i])) { alloc_nid_failed(sbi, nids[i]); mutex_unlock_op(sbi, NODE_NEW); err = PTR_ERR(npage[i]); goto release_pages; } set_nid(parent, offset[i - 1 ], nids[i], i == 1 ); alloc_nid_done(sbi, nids[i]); mutex_unlock_op(sbi, NODE_NEW); done = true ; } else if (ro && i == level && level > 1 ) { npage[i] = get_node_page_ra(parent, offset[i - 1 ]); if (IS_ERR(npage[i])) { err = PTR_ERR(npage[i]); goto release_pages; } done = true ; } if (i == 1 ) { dn->inode_page_locked = false ; unlock_page(parent); } else { f2fs_put_page(parent, 1 ); } if (!done) { npage[i] = get_node_page(sbi, nids[i]); if (IS_ERR(npage[i])) { err = PTR_ERR(npage[i]); f2fs_put_page(npage[0 ], 0 ); goto release_out; } } if (i < level) { parent = npage[i]; nids[i + 1 ] = get_nid(parent, offset[i], false ); } } dn->nid = nids[level]; dn->ofs_in_node = offset[level]; dn->node_page = npage[level]; dn->data_blkaddr = datablock_addr(dn->node_page, dn->ofs_in_node); return 0 ; release_pages: f2fs_put_page(parent, 1 ); if (i > 1 ) f2fs_put_page(npage[0 ], 0 ); release_out: dn->inode_page = NULL ; dn->node_page = NULL ; return err; }
F2FS 的 writeback 实际靠 do_write_data_page 完成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 int do_write_data_page (struct page *page) { struct inode *inode = struct f2fs_sb_info *sbi = block_t old_blk_addr, new_blk_addr; struct dnode_of_data dn ; int err = 0 ; set_new_dnode(&dn, inode, NULL , NULL , 0 ); err = get_dnode_of_data(&dn, page->index, RDONLY_NODE); if (err) return err; old_blk_addr = dn.data_blkaddr; if (old_blk_addr == NULL_ADDR) goto out_writepage; set_page_writeback(page); if (old_blk_addr != NEW_ADDR && !is_cold_data(page) && need_inplace_update(inode)) { rewrite_data_page(F2FS_SB(inode->i_sb), page, old_blk_addr); } else { write_data_page(inode, page, &dn, old_blk_addr, &new_blk_addr); update_extent_cache(new_blk_addr, &dn); F2FS_I(inode)->data_version = le64_to_cpu(F2FS_CKPT(sbi)->checkpoint_ver); } out_writepage: f2fs_put_dnode(&dn); return err; }
实际的写操作是区分为原地写和追加写
In-place write:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 void rewrite_data_page (struct f2fs_sb_info *sbi, struct page *page, block_t old_blk_addr) { submit_write_page(sbi, page, old_blk_addr, DATA); } static void submit_write_page (struct f2fs_sb_info *sbi, struct page *page, block_t blk_addr, enum page_type type) { struct block_device *bdev = verify_block_addr(sbi, blk_addr); down_write(&sbi->bio_sem); inc_page_count(sbi, F2FS_WRITEBACK); if (sbi->bio[type] && sbi->last_block_in_bio[type] != blk_addr - 1 ) do_submit_bio(sbi, type, false ); alloc_new: if (sbi->bio[type] == NULL ) { sbi->bio[type] = f2fs_bio_alloc(bdev, bio_get_nr_vecs(bdev)); sbi->bio[type]->bi_sector = SECTOR_FROM_BLOCK(sbi, blk_addr); } if (bio_add_page(sbi->bio[type], page, PAGE_CACHE_SIZE, 0 ) < PAGE_CACHE_SIZE) { do_submit_bio(sbi, type, false ); goto alloc_new; } sbi->last_block_in_bio[type] = blk_addr; up_write(&sbi->bio_sem); } static void do_submit_bio (struct f2fs_sb_info *sbi, enum page_type type, bool sync) { int rw = sync ? WRITE_SYNC : WRITE; enum page_type btype = if (type >= META_FLUSH) rw = WRITE_FLUSH_FUA; if (sbi->bio[btype]) { struct bio_private *p = p->sbi = sbi; sbi->bio[btype]->bi_end_io = f2fs_end_io_write; if (type == META_FLUSH) { DECLARE_COMPLETION_ONSTACK(wait); p->is_sync = true ; p->wait = &wait; submit_bio(rw, sbi->bio[btype]); wait_for_completion(&wait); } else { p->is_sync = false ; submit_bio(rw, sbi->bio[btype]); } sbi->bio[btype] = NULL ; } }
Append write
在追加写中,new_blkaddr 是由 callee 而非 caller 指定的,因此执行过程后调用方才能得知新的追加地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 void write_data_page (struct inode *inode, struct page *page, struct dnode_of_data *dn, block_t old_blkaddr, block_t *new_blkaddr) { struct f2fs_sb_info *sbi = struct f2fs_summary sum ; struct node_info ni ; BUG_ON(old_blkaddr == NULL_ADDR); get_node_info(sbi, dn->nid, &ni); set_summary(&sum, dn->nid, dn->ofs_in_node, ni.version); do_write_page(sbi, page, old_blkaddr, new_blkaddr, &sum, DATA); } static inline void set_summary (struct f2fs_summary *sum, nid_t nid, unsigned int ofs_in_node, unsigned char version) { sum->nid = cpu_to_le32(nid); sum->ofs_in_node = cpu_to_le16(ofs_in_node); sum->version = version; } static void do_write_page (struct f2fs_sb_info *sbi, struct page *page, block_t old_blkaddr, block_t *new_blkaddr, struct f2fs_summary *sum, enum page_type p_type) { struct sit_info *sit_i = struct curseg_info *curseg ; unsigned int old_cursegno; int type; type = __get_segment_type(page, p_type); curseg = CURSEG_I(sbi, type); mutex_lock(&curseg->curseg_mutex); *new_blkaddr = NEXT_FREE_BLKADDR(sbi, curseg); old_cursegno = curseg->segno; __add_sum_entry(sbi, type, sum, curseg->next_blkoff); mutex_lock(&sit_i->sentry_lock); __refresh_next_blkoff(sbi, curseg); sbi->block_count[curseg->alloc_type]++; refresh_sit_entry(sbi, old_blkaddr, *new_blkaddr); if (!__has_curseg_space(sbi, type)) sit_i->s_ops->allocate_segment(sbi, type, false ); locate_dirty_segment(sbi, old_cursegno); locate_dirty_segment(sbi, GET_SEGNO(sbi, old_blkaddr)); mutex_unlock(&sit_i->sentry_lock); if (p_type == NODE) fill_node_footer_blkaddr(page, NEXT_FREE_BLKADDR(sbi, curseg)); submit_write_page(sbi, page, *new_blkaddr, p_type); mutex_unlock(&curseg->curseg_mutex); }
read operation
F2FS的读流程包含了以下几个子流程:
vfs_read 函数
generic_file_read_iter 函数: 根据访问类型执行不同的处理
generic_file_buffered_read: 根据用户传入的文件偏移,读取尺寸等信息,计算起始位置和页数,然后遍历每一个 page,通过预读或者单个读取的方式从磁盘中读取出来
f2fs_read_data_page & f2fs_read_data_pages 函数: 从磁盘读取1个 page 或者多个 page
f2fs_mpage_readpages 函数: f2fs 读取数据的主流程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 static int f2fs_read_data_page (struct file *file, struct page *page) { struct inode *inode = int ret = -EAGAIN; trace_f2fs_readpage(page, DATA); if (f2fs_has_inline_data(inode)) ret = f2fs_read_inline_data(inode, page); ret = f2fs_mpage_readpages(page->mapping, NULL , page, 1 ); return ret; } static int f2fs_read_data_pages (struct file *file, struct address_space *mapping, struct list_head *pages, unsigned nr_pages) { struct inode *inode = struct page *page =struct page, lru); trace_f2fs_readpages(inode, page, nr_pages); if (f2fs_has_inline_data(inode)) return 0 ; return f2fs_mpage_readpages(mapping, pages, NULL , nr_pages); }
第二个参数表示一个链表头,这个链表保存了多个page,因此需要写入多个page的时候,就要传入一个List。 第三个参数表示单个page,在写入单个page的时候,通过这个函数写入。 第四个参数表示需要写入page的数目。
因此 在写入多个page的时候,需要设定第二个参数,和第四个参数,然后设定第三个参数为NULL。 在写入单个page的时候,需要设定第三个参数,和第四个参数,然后设定第二个参数为NULL。
然后分析这个函数的执行流程:
遍历传入的page,得到每一个page的index以及inode
将page的inode以及index传入 f2fs_map_blocks 函数获取到该page的物理地址
将物理地址通过 submit_bio 读取该page在磁盘中的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 static int f2fs_mpage_readpages (struct address_space *mapping, struct list_head *pages, struct page *page, unsigned nr_pages) { struct f2fs_map_blocks map ; map .m_pblk = 0 ; map .m_lblk = 0 ; map .m_len = 0 ; map .m_flags = 0 ; map .m_next_pgofs = NULL ; for (page_idx = 0 ; nr_pages; page_idx++, nr_pages--) { if (pages) { page = list_entry(pages->prev, struct page, lru); list_del(&page->lru); if (add_to_page_cache_lru(page, mapping, page->index, GFP_KERNEL)) goto next_page; } if ((map .m_flags & F2FS_MAP_MAPPED) && block_in_file > map .m_lblk && block_in_file < (map .m_lblk + map .m_len)) goto got_it; map .m_flags = 0 ; if (block_in_file < last_block) { map .m_lblk = block_in_file; map .m_len = last_block - block_in_file; if (f2fs_map_blocks(inode, &map , 0 , F2FS_GET_BLOCK_READ)) goto set_error_page; } got_it: if ((map .m_flags & F2FS_MAP_MAPPED)) { block_nr = map .m_pblk + block_in_file - map .m_lblk; SetPageMappedToDisk(page); if (!PageUptodate(page) && !cleancache_get_page(page)) { SetPageUptodate(page); goto confused; } } else { zero_user_segment(page, 0 , PAGE_SIZE); SetPageUptodate(page); unlock_page(page); goto next_page; } if (bio && (last_block_in_bio != block_nr - 1 )) { submit_and_realloc: submit_bio(READ, bio); bio = NULL ; } if (bio == NULL ) { struct fscrypt_ctx *ctx =NULL ; if (f2fs_encrypted_inode(inode) && S_ISREG(inode->i_mode)) { ctx = fscrypt_get_ctx(inode, GFP_NOFS); if (IS_ERR(ctx)) goto set_error_page; f2fs_wait_on_encrypted_page_writeback( F2FS_I_SB(inode), block_nr); } bio = bio_alloc(GFP_KERNEL, min_t (int , nr_pages, BIO_MAX_PAGES)); if (!bio) { if (ctx) fscrypt_release_ctx(ctx); goto set_error_page; } bio->bi_bdev = bdev; bio->bi_iter.bi_sector = SECTOR_FROM_BLOCK(block_nr); bio->bi_end_io = f2fs_read_end_io; bio->bi_private = ctx; } if (bio_add_page(bio, page, blocksize, 0 ) < blocksize) goto submit_and_realloc; set_error_page: SetPageError(page); zero_user_segment(page, 0 , PAGE_SIZE); unlock_page(page); goto next_page; confused: if (bio) { submit_bio(READ, bio); bio = NULL ; } unlock_page(page); next_page: if (pages) put_page(page); } BUG_ON(pages && !list_empty(pages)); if (bio) submit_bio(READ, bio); return 0 ; }
garbage collection
F2FS 的 GC 入口在 f2fs_gc()。这个函数的 caller 有 2 个:
一个是前面接触到的 f2fs_balance_fs()
另一个是后台 kthread 执行的 gc_thread_func()
Background GC
f2fs_fill_super() 初始化执行了 start_gc_thread()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 int start_gc_thread (struct f2fs_sb_info *sbi) { struct f2fs_gc_kthread *gc_th ; gc_th = kmalloc(sizeof (struct f2fs_gc_kthread), GFP_KERNEL); if (!gc_th) return -ENOMEM; sbi->gc_thread = gc_th; init_waitqueue_head(&sbi->gc_thread->gc_wait_queue_head); sbi->gc_thread->f2fs_gc_task = kthread_run(gc_thread_func, sbi, GC_THREAD_NAME); if (IS_ERR(gc_th->f2fs_gc_task)) { kfree(gc_th); return -ENOMEM; } return 0 ; } static int gc_thread_func (void *data) { struct f2fs_sb_info *sbi = wait_queue_head_t *wq = &sbi->gc_thread->gc_wait_queue_head; long wait_ms; wait_ms = GC_THREAD_MIN_SLEEP_TIME; do { if (try_to_freeze()) continue ; else wait_event_interruptible_timeout(*wq, kthread_should_stop(), msecs_to_jiffies(wait_ms)); if (kthread_should_stop()) break ; f2fs_balance_fs(sbi); if (!test_opt(sbi, BG_GC)) continue ; if (!mutex_trylock(&sbi->gc_mutex)) continue ; if (!is_idle(sbi)) { wait_ms = increase_sleep_time(wait_ms); mutex_unlock(&sbi->gc_mutex); continue ; } if (has_enough_invalid_blocks(sbi)) wait_ms = decrease_sleep_time(wait_ms); else wait_ms = increase_sleep_time(wait_ms); sbi->bg_gc++; if (f2fs_gc(sbi) == GC_NONE) wait_ms = GC_THREAD_NOGC_SLEEP_TIME; else if (wait_ms == GC_THREAD_NOGC_SLEEP_TIME) wait_ms = GC_THREAD_MAX_SLEEP_TIME; } while (!kthread_should_stop()); return 0 ; } static inline bool has_enough_invalid_blocks (struct f2fs_sb_info *sbi) { block_t invalid_user_blocks = sbi->user_block_count - written_block_count(sbi); if (invalid_user_blocks > limit_invalid_user_blocks(sbi) && free_user_blocks(sbi) < limit_free_user_blocks(sbi)) return true ; return false ; } static inline long decrease_sleep_time (long wait) { wait -= GC_THREAD_MIN_SLEEP_TIME; if (wait <= GC_THREAD_MIN_SLEEP_TIME) wait = GC_THREAD_MIN_SLEEP_TIME; return wait; } static inline long increase_sleep_time (long wait) { wait += GC_THREAD_MIN_SLEEP_TIME; if (wait > GC_THREAD_MAX_SLEEP_TIME) wait = GC_THREAD_MAX_SLEEP_TIME; return wait; }
主流程
不管前台 GC 还是后台 GC,都会进入到统一的 GC 接口 f2fs_gc()。后台 GC 的情况在前面已经说明了;而前台 GC 可能会通过 f2fs_balance_fs() 在多个流程插入,只要 free section 低于预期,就会进入主流程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 int f2fs_gc (struct f2fs_sb_info *sbi) { struct list_head ilist ; unsigned int segno, i; int gc_type = BG_GC; int gc_status = GC_NONE; INIT_LIST_HEAD(&ilist); gc_more: if (!(sbi->sb->s_flags & MS_ACTIVE)) goto stop; if (has_not_enough_free_secs(sbi)) gc_type = FG_GC; if (!__get_victim(sbi, &segno, gc_type, NO_CHECK_TYPE)) goto stop; for (i = 0 ; i < sbi->segs_per_sec; i++) { gc_status = do_garbage_collect(sbi, segno + i, &ilist, gc_type); if (gc_status != GC_DONE) break ; } if (has_not_enough_free_secs(sbi)) { write_checkpoint(sbi, (gc_status == GC_BLOCKED), false ); if (has_not_enough_free_secs(sbi)) goto gc_more; } stop: mutex_unlock(&sbi->gc_mutex); put_gc_inode(&ilist); return gc_status; }
在 GC 真正执行前,需要挑选 victim
Victim selection
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 static int __get_victim(struct f2fs_sb_info *sbi, unsigned int *victim, int gc_type, int type) { struct sit_info *sit_i = int ret; mutex_lock(&sit_i->sentry_lock); ret = DIRTY_I(sbi)->v_ops->get_victim(sbi, victim, gc_type, type, LFS); mutex_unlock(&sit_i->sentry_lock); return ret; } struct victim_selection { int (*get_victim)(struct f2fs_sb_info *, unsigned int *, int , int , char ); }; static const struct victim_selection default_v_ops = .get_victim = get_victim_by_default, }; static int get_victim_by_default (struct f2fs_sb_info *sbi, unsigned int *result, int gc_type, int type, char alloc_mode) { struct dirty_seglist_info *dirty_i = struct victim_sel_policy p ; unsigned int segno; int nsearched = 0 ; p.alloc_mode = alloc_mode; select_policy(sbi, gc_type, type, &p); p.min_segno = NULL_SEGNO; p.min_cost = get_max_cost(sbi, &p); mutex_lock(&dirty_i->seglist_lock); if (p.alloc_mode == LFS && gc_type == FG_GC) { p.min_segno = check_bg_victims(sbi); if (p.min_segno != NULL_SEGNO) goto got_it; } while (1 ) { unsigned long cost; segno = find_next_bit(p.dirty_segmap, TOTAL_SEGS(sbi), p.offset); if (segno >= TOTAL_SEGS(sbi)) { if (sbi->last_victim[p.gc_mode]) { sbi->last_victim[p.gc_mode] = 0 ; p.offset = 0 ; continue ; } break ; } p.offset = ((segno / p.ofs_unit) * p.ofs_unit) + p.ofs_unit; if (test_bit(segno, dirty_i->victim_segmap[FG_GC])) continue ; if (gc_type == BG_GC && test_bit(segno, dirty_i->victim_segmap[BG_GC])) continue ; if (IS_CURSEC(sbi, GET_SECNO(sbi, segno))) continue ; cost = get_gc_cost(sbi, segno, &p); if (p.min_cost > cost) { p.min_segno = segno; p.min_cost = cost; } if (cost == get_max_cost(sbi, &p)) continue ; if (nsearched++ >= MAX_VICTIM_SEARCH) { sbi->last_victim[p.gc_mode] = segno; break ; } } got_it: if (p.min_segno != NULL_SEGNO) { *result = (p.min_segno / p.ofs_unit) * p.ofs_unit; if (p.alloc_mode == LFS) { int i; for (i = 0 ; i < p.ofs_unit; i++) set_bit(*result + i, dirty_i->victim_segmap[gc_type]); } } mutex_unlock(&dirty_i->seglist_lock); return (p.min_segno == NULL_SEGNO) ? 0 : 1 ; } static void select_policy (struct f2fs_sb_info *sbi, int gc_type, int type, struct victim_sel_policy *p) { struct dirty_seglist_info *dirty_i = if (p->alloc_mode) { p->gc_mode = GC_GREEDY; p->dirty_segmap = dirty_i->dirty_segmap[type]; p->ofs_unit = 1 ; } else { p->gc_mode = select_gc_type(gc_type); p->dirty_segmap = dirty_i->dirty_segmap[DIRTY]; p->ofs_unit = sbi->segs_per_sec; } p->offset = sbi->last_victim[p->gc_mode]; } static unsigned int get_max_cost (struct f2fs_sb_info *sbi, struct victim_sel_policy *p) { if (p->gc_mode == GC_GREEDY) return (1 << sbi->log_blocks_per_seg) * p->ofs_unit; else if (p->gc_mode == GC_CB) return UINT_MAX; else return 0 ; } static unsigned int check_bg_victims (struct f2fs_sb_info *sbi) { struct dirty_seglist_info *dirty_i = unsigned int segno; segno = find_next_bit(dirty_i->victim_segmap[BG_GC], TOTAL_SEGS(sbi), 0 ); if (segno < TOTAL_SEGS(sbi)) { clear_bit(segno, dirty_i->victim_segmap[BG_GC]); return segno; } return NULL_SEGNO; } static unsigned int get_gc_cost (struct f2fs_sb_info *sbi, unsigned int segno, struct victim_sel_policy *p) { if (p->alloc_mode == SSR) return get_seg_entry(sbi, segno)->ckpt_valid_blocks; if (p->gc_mode == GC_GREEDY) return get_valid_blocks(sbi, segno, sbi->segs_per_sec); else return get_cb_cost(sbi, segno); } static unsigned int get_cb_cost (struct f2fs_sb_info *sbi, unsigned int segno) { struct sit_info *sit_i = unsigned int secno = GET_SECNO(sbi, segno); unsigned int start = secno * sbi->segs_per_sec; unsigned long long mtime = 0 ; unsigned int vblocks; unsigned char age = 0 ; unsigned char u; unsigned int i; for (i = 0 ; i < sbi->segs_per_sec; i++) mtime += get_seg_entry(sbi, start + i)->mtime; vblocks = get_valid_blocks(sbi, segno, sbi->segs_per_sec); mtime = div_u64(mtime, sbi->segs_per_sec); vblocks = div_u64(vblocks, sbi->segs_per_sec); u = (vblocks * 100 ) >> sbi->log_blocks_per_seg; if (mtime < sit_i->min_mtime) sit_i->min_mtime = mtime; if (mtime > sit_i->max_mtime) sit_i->max_mtime = mtime; if (sit_i->max_mtime != sit_i->min_mtime) age = 100 - div64_u64(100 * (mtime - sit_i->min_mtime), sit_i->max_mtime - sit_i->min_mtime); return UINT_MAX - ((100 * (100 - u) * age) / (100 + u)); }
GC procedure
处理[ s e g n o , s e g n o + s e g m e n t s _ p e r _ s e c t i o n ) \left[segno,\; segno+segments\_per\_section\right) [ se g n o , se g n o + se g m e n t s _ p er _ sec t i o n )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 static int do_garbage_collect (struct f2fs_sb_info *sbi, unsigned int segno, struct list_head *ilist, int gc_type) { struct page *sum_page ; struct f2fs_summary_block *sum ; int ret = GC_DONE; sum_page = get_sum_page(sbi, segno); if (IS_ERR(sum_page)) return GC_ERROR; unlock_page(sum_page); sum = page_address(sum_page); switch (GET_SUM_TYPE((&sum->footer))) { case SUM_TYPE_NODE: ret = gc_node_segment(sbi, sum->entries, segno, gc_type); break ; case SUM_TYPE_DATA: ret = gc_data_segment(sbi, sum->entries, ilist, segno, gc_type); break ; } stat_inc_seg_count(sbi, GET_SUM_TYPE((&sum->footer))); stat_inc_call_count(sbi->stat_info); f2fs_put_page(sum_page, 0 ); return ret; } static int gc_data_segment (struct f2fs_sb_info *sbi, struct f2fs_summary *sum, struct list_head *ilist, unsigned int segno, int gc_type) { struct super_block *sb = struct f2fs_summary *entry ; block_t start_addr; int err, off; int phase = 0 ; start_addr = START_BLOCK(sbi, segno); next_step: entry = sum; for (off = 0 ; off < sbi->blocks_per_seg; off++, entry++) { struct page *data_page ; struct inode *inode ; struct node_info dni ; unsigned int ofs_in_node, nofs; block_t start_bidx; if (should_do_checkpoint(sbi)) { mutex_lock(&sbi->cp_mutex); block_operations(sbi); err = GC_BLOCKED; goto stop; } err = check_valid_map(sbi, segno, off); if (err == GC_NEXT) continue ; if (phase == 0 ) { ra_node_page(sbi, le32_to_cpu(entry->nid)); continue ; } err = check_dnode(sbi, entry, &dni, start_addr + off, &nofs); if (err == GC_NEXT) continue ; if (phase == 1 ) { ra_node_page(sbi, dni.ino); continue ; } start_bidx = start_bidx_of_node(nofs); ofs_in_node = le16_to_cpu(entry->ofs_in_node); if (phase == 2 ) { inode = f2fs_iget_nowait(sb, dni.ino); if (IS_ERR(inode)) continue ; data_page = find_data_page(inode, start_bidx + ofs_in_node); if (IS_ERR(data_page)) goto next_iput; f2fs_put_page(data_page, 0 ); add_gc_inode(inode, ilist); } else { inode = find_gc_inode(dni.ino, ilist); if (inode) { data_page = get_lock_data_page(inode, start_bidx + ofs_in_node); if (IS_ERR(data_page)) continue ; move_data_page(inode, data_page, gc_type); stat_inc_data_blk_count(sbi, 1 ); } } continue ; next_iput: iput(inode); } if (++phase < 4 ) goto next_step; err = GC_DONE; stop: if (gc_type == FG_GC) f2fs_submit_bio(sbi, DATA, true ); return err; } static void add_gc_inode (struct inode *inode, struct list_head *ilist) { struct list_head *this ; struct inode_entry *new_ie , *ie ; list_for_each(this, ilist) { ie = list_entry(this, struct inode_entry, list ); if (ie->inode == inode) { iput(inode); return ; } } repeat: new_ie = kmem_cache_alloc(winode_slab, GFP_NOFS); if (!new_ie) { cond_resched(); goto repeat; } new_ie->inode = inode; list_add_tail(&new_ie->list , ilist); } static struct inode *find_gc_inode (nid_t ino, struct list_head *ilist) { struct list_head *this ; struct inode_entry *ie ; list_for_each(this, ilist) { ie = list_entry(this, struct inode_entry, list ); if (ie->inode->i_ino == ino) return ie->inode; } return NULL ; } static void move_data_page (struct inode *inode, struct page *page, int gc_type) { if (page->mapping != inode->i_mapping) goto out; if (inode != page->mapping->host) goto out; if (PageWriteback(page)) goto out; if (gc_type == BG_GC) { set_page_dirty(page); set_cold_data(page); } else { struct f2fs_sb_info *sbi = F2FS_SB(inode->i_sb); mutex_lock_op(sbi, DATA_WRITE); if (clear_page_dirty_for_io(page) && S_ISDIR(inode->i_mode)) { dec_page_count(sbi, F2FS_DIRTY_DENTS); inode_dec_dirty_dents(inode); } set_cold_data(page); do_write_data_page(page); mutex_unlock_op(sbi, DATA_WRITE); clear_cold_data(page); } out: f2fs_put_page(page, 1 ); }
Recovery
触发 checkpoint 的主流程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 void write_checkpoint (struct f2fs_sb_info *sbi, bool blocked, bool is_umount) { struct f2fs_checkpoint *ckpt = unsigned long long ckpt_ver; if (!blocked) { mutex_lock(&sbi->cp_mutex); block_operations(sbi); } f2fs_submit_bio(sbi, DATA, true ); f2fs_submit_bio(sbi, NODE, true ); f2fs_submit_bio(sbi, META, true ); ckpt_ver = le64_to_cpu(ckpt->checkpoint_ver); ckpt->checkpoint_ver = cpu_to_le64(++ckpt_ver); flush_nat_entries(sbi); flush_sit_entries(sbi); reset_victim_segmap(sbi); do_checkpoint(sbi, is_umount); unblock_operations(sbi); mutex_unlock(&sbi->cp_mutex); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 static void do_checkpoint (struct f2fs_sb_info *sbi, bool is_umount) { struct f2fs_checkpoint *ckpt = nid_t last_nid = 0 ; block_t start_blk; struct page *cp_page ; unsigned int data_sum_blocks, orphan_blocks; unsigned int crc32 = 0 ; void *kaddr; int i; while (get_pages(sbi, F2FS_DIRTY_META)) sync_meta_pages(sbi, META, LONG_MAX); next_free_nid(sbi, &last_nid); ckpt->elapsed_time = cpu_to_le64(get_mtime(sbi)); ckpt->valid_block_count = cpu_to_le64(valid_user_blocks(sbi)); ckpt->free_segment_count = cpu_to_le32(free_segments(sbi)); for (i = 0 ; i < 3 ; i++) { ckpt->cur_node_segno[i] = cpu_to_le32(curseg_segno(sbi, i + CURSEG_HOT_NODE)); ckpt->cur_node_blkoff[i] = cpu_to_le16(curseg_blkoff(sbi, i + CURSEG_HOT_NODE)); ckpt->alloc_type[i + CURSEG_HOT_NODE] = curseg_alloc_type(sbi, i + CURSEG_HOT_NODE); } for (i = 0 ; i < 3 ; i++) { ckpt->cur_data_segno[i] = cpu_to_le32(curseg_segno(sbi, i + CURSEG_HOT_DATA)); ckpt->cur_data_blkoff[i] = cpu_to_le16(curseg_blkoff(sbi, i + CURSEG_HOT_DATA)); ckpt->alloc_type[i + CURSEG_HOT_DATA] = curseg_alloc_type(sbi, i + CURSEG_HOT_DATA); } ckpt->valid_node_count = cpu_to_le32(valid_node_count(sbi)); ckpt->valid_inode_count = cpu_to_le32(valid_inode_count(sbi)); ckpt->next_free_nid = cpu_to_le32(last_nid); data_sum_blocks = npages_for_summary_flush(sbi); if (data_sum_blocks < 3 ) set_ckpt_flags(ckpt, CP_COMPACT_SUM_FLAG); else clear_ckpt_flags(ckpt, CP_COMPACT_SUM_FLAG); orphan_blocks = (sbi->n_orphans + F2FS_ORPHANS_PER_BLOCK - 1 ) / F2FS_ORPHANS_PER_BLOCK; ckpt->cp_pack_start_sum = cpu_to_le32(1 + orphan_blocks); if (is_umount) { set_ckpt_flags(ckpt, CP_UMOUNT_FLAG); ckpt->cp_pack_total_block_count = cpu_to_le32(2 + data_sum_blocks + orphan_blocks + NR_CURSEG_NODE_TYPE); } else { clear_ckpt_flags(ckpt, CP_UMOUNT_FLAG); ckpt->cp_pack_total_block_count = cpu_to_le32(2 + data_sum_blocks + orphan_blocks); } if (sbi->n_orphans) set_ckpt_flags(ckpt, CP_ORPHAN_PRESENT_FLAG); else clear_ckpt_flags(ckpt, CP_ORPHAN_PRESENT_FLAG); get_sit_bitmap(sbi, __bitmap_ptr(sbi, SIT_BITMAP)); get_nat_bitmap(sbi, __bitmap_ptr(sbi, NAT_BITMAP)); crc32 = f2fs_crc32(ckpt, le32_to_cpu(ckpt->checksum_offset)); *(__le32 *)((unsigned char *)ckpt + le32_to_cpu(ckpt->checksum_offset)) = cpu_to_le32(crc32); start_blk = __start_cp_addr(sbi); cp_page = grab_meta_page(sbi, start_blk++); kaddr = page_address(cp_page); memcpy (kaddr, ckpt, (1 << sbi->log_blocksize)); set_page_dirty(cp_page); f2fs_put_page(cp_page, 1 ); if (sbi->n_orphans) { write_orphan_inodes(sbi, start_blk); start_blk += orphan_blocks; } write_data_summaries(sbi, start_blk); start_blk += data_sum_blocks; if (is_umount) { write_node_summaries(sbi, start_blk); start_blk += NR_CURSEG_NODE_TYPE; } cp_page = grab_meta_page(sbi, start_blk); kaddr = page_address(cp_page); memcpy (kaddr, ckpt, (1 << sbi->log_blocksize)); set_page_dirty(cp_page); f2fs_put_page(cp_page, 1 ); while (get_pages(sbi, F2FS_WRITEBACK)) congestion_wait(BLK_RW_ASYNC, HZ / 50 ); filemap_fdatawait_range(sbi->node_inode->i_mapping, 0 , LONG_MAX); filemap_fdatawait_range(sbi->meta_inode->i_mapping, 0 , LONG_MAX); sbi->last_valid_block_count = sbi->total_valid_block_count; sbi->alloc_valid_block_count = 0 ; if (is_set_ckpt_flags(ckpt, CP_ERROR_FLAG)) sbi->sb->s_flags |= MS_RDONLY; else sync_meta_pages(sbi, META_FLUSH, LONG_MAX); clear_prefree_segments(sbi); F2FS_RESET_SB_DIRT(sbi); } int npages_for_summary_flush (struct f2fs_sb_info *sbi) { int total_size_bytes = 0 ; int valid_sum_count = 0 ; int i, sum_space; for (i = CURSEG_HOT_DATA; i <= CURSEG_COLD_DATA; i++) { if (sbi->ckpt->alloc_type[i] == SSR) valid_sum_count += sbi->blocks_per_seg; else valid_sum_count += curseg_blkoff(sbi, i); } total_size_bytes = valid_sum_count * (SUMMARY_SIZE + 1 ) + sizeof (struct nat_journal) + 2 + sizeof (struct sit_journal) + 2 ; sum_space = PAGE_CACHE_SIZE - SUM_FOOTER_SIZE; if (total_size_bytes < sum_space) return 1 ; else if (total_size_bytes < 2 * sum_space) return 2 ; return 3 ; } static inline block_t __start_cp_addr(struct f2fs_sb_info *sbi){ block_t start_addr = le32_to_cpu(F2FS_RAW_SUPER(sbi)->cp_blkaddr); if (sbi->cur_cp_pack == 2 ) start_addr += sbi->blocks_per_seg; return start_addr; } void write_data_summaries (struct f2fs_sb_info *sbi, block_t start_blk) { if (is_set_ckpt_flags(F2FS_CKPT(sbi), CP_COMPACT_SUM_FLAG)) write_compacted_summaries(sbi, start_blk); else write_normal_summaries(sbi, start_blk, CURSEG_HOT_DATA); } static void write_compacted_summaries (struct f2fs_sb_info *sbi, block_t blkaddr) { struct page *page ; unsigned char *kaddr; struct f2fs_summary *summary ; struct curseg_info *seg_i ; int written_size = 0 ; int i, j; page = grab_meta_page(sbi, blkaddr++); kaddr = (unsigned char *)page_address(page); seg_i = CURSEG_I(sbi, CURSEG_HOT_DATA); memcpy (kaddr, &seg_i->sum_blk->n_nats, SUM_JOURNAL_SIZE); written_size += SUM_JOURNAL_SIZE; seg_i = CURSEG_I(sbi, CURSEG_COLD_DATA); memcpy (kaddr + written_size, &seg_i->sum_blk->n_sits, SUM_JOURNAL_SIZE); written_size += SUM_JOURNAL_SIZE; set_page_dirty(page); for (i = CURSEG_HOT_DATA; i <= CURSEG_COLD_DATA; i++) { unsigned short blkoff; seg_i = CURSEG_I(sbi, i); if (sbi->ckpt->alloc_type[i] == SSR) blkoff = sbi->blocks_per_seg; else blkoff = curseg_blkoff(sbi, i); for (j = 0 ; j < blkoff; j++) { if (!page) { page = grab_meta_page(sbi, blkaddr++); kaddr = (unsigned char *)page_address(page); written_size = 0 ; } summary = (struct f2fs_summary *)(kaddr + written_size); *summary = seg_i->sum_blk->entries[j]; written_size += SUMMARY_SIZE; set_page_dirty(page); if (written_size + SUMMARY_SIZE <= PAGE_CACHE_SIZE - SUM_FOOTER_SIZE) continue ; f2fs_put_page(page, 1 ); page = NULL ; } } if (page) f2fs_put_page(page, 1 ); } static void write_normal_summaries (struct f2fs_sb_info *sbi, block_t blkaddr, int type) { int i, end; if (IS_DATASEG(type)) end = type + NR_CURSEG_DATA_TYPE; else end = type + NR_CURSEG_NODE_TYPE; for (i = type; i < end; i++) { struct curseg_info *sum = mutex_lock(&sum->curseg_mutex); write_sum_page(sbi, sum->sum_blk, blkaddr + (i - type)); mutex_unlock(&sum->curseg_mutex); } }